MongoDB Support is Here

We're thrilled to announce first-class MongoDB support in Pluk. For years, developers have told us they love MongoDB's flexibility — but also that exploring deeply nested documents, debugging aggregations, and making sense of schemaless data can feel messy. Pluk brings clarity: a clean, visual document explorer, intelligent aggregation generation, realtime views, and developer-friendly performance tooling — all wrapped in the same local-first, privacy-minded experience you expect from Pluk.
What Pluk Brings to MongoDB
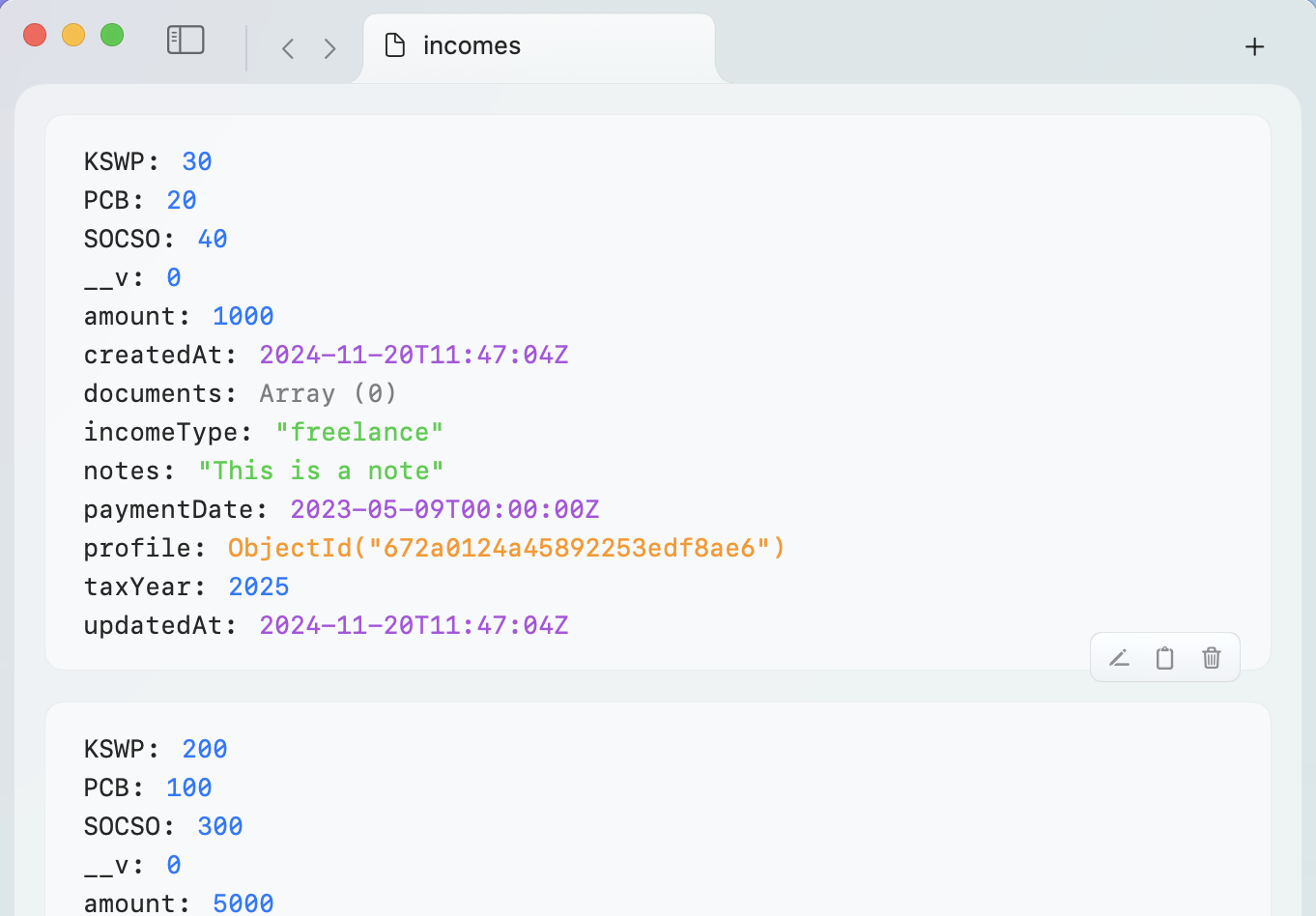
Document Viewer — Beautiful, Expandable JSON
Browse collections with an expandable JSON tree that preserves structure and context. Click into nested arrays, inspect object shapes, collapse/expand fields, and preview large documents without losing performance. The viewer supports:
- Inline field previews
- Type hints for common BSON types (Date, ObjectId, Decimal128)
- Quick copy of field paths for use in queries
Aggregation Pipelines — Built From Plain English
Writing aggregation pipelines can be tedious. Tell Pluk what you want in plain English — "users with more than 5 purchases last year, joined with their profiles" — and we propose a pipeline you can review, tweak, and run. Pipelines are shown with step-by-step explanations, so you learn while you work.
Realtime Insights — Change Streams Visualized
See live updates from your collections with change-stream-driven views. When documents insert, update, or delete, Pluk highlights the changes in context so you can debug live systems, verify replication, or watch test data evolve — useful for live debugging and demos.
Schema Intelligence — Understand What’s Really in Your Data
Even schemaless data has patterns. Pluk scans a sample of your collection and surfaces:
- Common field shapes
- Optional vs required fields
- Type variance (string vs number in the same field) This helps make smarter query suggestions and lets you generate type-safe views or migrations.
Performance & Index Recommendations
Run explain plans from the UI and get plain-English analysis of slow queries. Pluk suggests indexes where appropriate and shows estimated improvements, helping you prioritize fixes with confidence.
Privacy-First, Local-First Workflow
Pluk keeps your data local-first: queries and analysis run from your machine. If you choose to connect cloud projects, Pluk syncs metadata securely; your raw data stays under your control.
Example: From English to Aggregation
You ask: "Find users who made more than 5 purchases and include the total spent, sorted by largest spend."
Pluk generates an aggregation pipeline like:
db.users.aggregate([
{
$lookup: {
from: "orders",
localField: "_id",
foreignField: "userId",
as: "orders"
}
},
{
$addFields: {
totalSpent: { $sum: "$orders.amount" },
orderCount: { $size: "$orders" }
}
},
{
$match: {
orderCount: { $gt: 5 }
}
},
{
$sort: { totalSpent: -1 }
},
{
$project: {
name: 1,
email: 1,
totalSpent: 1,
orderCount: 1
}
}
])
You can preview results inline, step through each stage, and adjust fields visually — no guesswork.
Why MongoDB + Pluk
MongoDB's flexible document model and Pluk's intelligent interface are a natural fit. Pluk helps you:
- Explore complex documents without getting lost
- Build and understand aggregations faster
- Debug realtime applications with live change feeds
- Make performance-driven improvements with actionable advice
Whether you’re building product features, running analytics, or iterating on a schema, Pluk turns noisy document stores into an understandable, navigable surface.
Try It Today
MongoDB support is available now in beta. Connect a project, open a collection, and tell Pluk what you want — we'll translate your intent into queries and help you ship faster.
We can't wait to see what you'll build. Send feedback, pipelines you want to optimize, or favorite MongoDB edge cases — we read every message.